انویدیا از نسخه جدید TensorRT 8 رونمایی کرد

فناوری TensorRT SDK یادگیری عمیق انویدیا است که اپلیکیشن ها را قادر می سازد تا 40 برابر سریعتر از پلتفرم های فقط CPU در هنگام استنتاج عمل کنند. با مدل برنامه نویسی موازی CUDA، این فناوری به شما امکان می دهد مدل های شبکه عصبی را بهینه کرده و برای دقت کمتر با دقت بالا کالیبره کنید و مدل های خود را برای موارد تحقیق و استفاده تجاری استفاده کنید.
امروز انویدیا نسل هشتم TensorRT را به بازار عرضه کرد. TensorRT 8 لقب گرفته و آخرین تکرار SDK مجموعه جدیدی از به روزرسانی ها و پیشرفت ها را به همراه دارد که به توسعه دهندگان و مشاغل اجازه می دهد تا گردش کار و محصولات یادگیری عمیق خود را در وب بهینه و استقرار دهند.
در استقرار و استفاده تجاری، زمان استنباط برای مدل های یادگیری عمیق می تواند گلوگاه هایی ایجاد کند، به ویژه برای مدل های بزرگ ترانسفورماتور مانند BERT و GPT-3. برای کاهش این موارد، توسعه دهندگان به کاهش پارامترها/اندازه مدل متوسل می شوند. اما این منجر به از دست دادن دقت و کاهش کیفیت در مدل کوچک شده می شود.
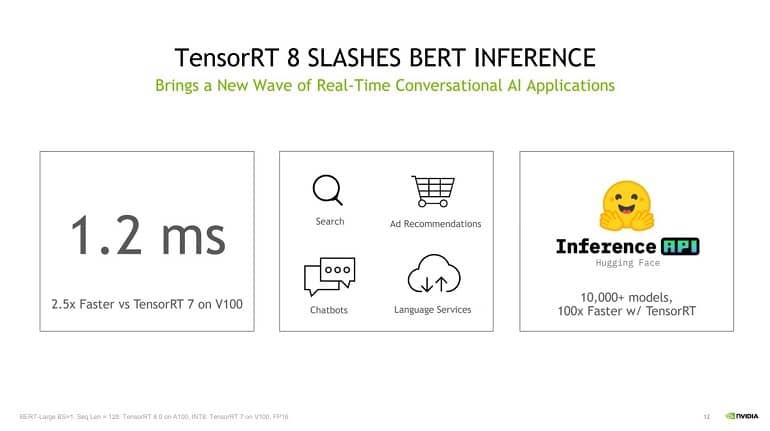
ابتدا با استفاده از TensorRT 8، در اولین صنعت، انویدیا زمان استنتاج 1.2 میلی ثانیه را در BERT-Large ثبت کرد که امروزه یکی از رایج ترین مدل های زبان است. در مقایسه با آخرین نسل TensorRT، زمان استنباط 1.2 میلی ثانیه در پردازنده گرافیکی V100 انویدیا 2.5 برابر سریعتر است. زمان استنباط در ثبت رکورد TensorRT 8 باید به مشاغل اجازه دهد تا بدون نگرانی بیش از حد در مورد قدرت محاسبه و زمان استنباط، از مدل های بزرگتر از این نوع زبان ها استفاده کنند.
در قلب این سرعت استنتاج سریع، دو پیشرفت اساسی نهفته است. در مرحله اول، TensorRT 8 از تکنیک عملکردی معروف به Sparsity استفاده می کند که با کاهش عملیات محاسباتی، استنتاج شبکه عصبی را سرعت می بخشد. Sparsity که از معماری Ampere انویدیا پشتیبانی می شود، بر ورودی های غیر صفر در لایه های پنهان شبکه عصبی متمرکز است و اساساً ورودی هایی را که بر جریان تانسور از طریق شبکه تأثیری ندارند، هرس می کند. این تعداد عملیات مورد نیاز برای محاسبه پاسخ در یک پاس رو به جلو را کاهش می دهد، و باعث می شود زمان استنتاج سریع در هنگام استقرار وجود داشته باشد.
تکنیک دوم که Quantization Aware Training (QAT) نامیده می شود، به توسعه دهندگان این امکان را می دهد تا بدون استفاده از دقت، از مدل های آموزش دیده برای اجرای استنتاج با دقت INT8 استفاده کنند. در مقایسه با دقت های INT32 و INT16 ، که به طور معمول برای آموزش و/یا استقرار استفاده می شود، INT8 با کاهش دقت اعداد، محاسبات سریع تری را ارائه می دهد، که به نوبه خود محاسبه و ذخیره سربار در هسته های تنسور را کاهش می دهد. اسپارسیتی، QAT و سایر بهینه سازی های خاص مدل پخته شده در TensorRT 8 به طور تجمعی منجر به 2 برابر عملکرد نسبت به مدل قبلی TensorRT 7 می شود.
خبر هیجان انگیز دیگر برای توسعه دهندگان این است که Huggingface، کتابخانه منبع باز مشهور و همه جا حاضر برای مدل های ترانسفورماتور، رسماً از TensorRT 8 پشتیبانی می کند و زمان استنتاج 1 میلی ثانیه را در اواخر سال جاری ثبت می کند.




