در ماههای اخیر، OpenAI ابزارهای جدیدی مانند Operator، Deep Research، Computer-Using Agents و Responses API را معرفی کرده که بر ایجنت های متنی تمرکز دارند. امروز، این شرکت مدلهای صوتی جدیدی برای تبدیل گفتار به متن و متن به گفتار در API خود معرفی کرد که به توسعهدهندگان امکان میدهد ایجنت های صوتی قدرتمندتر، قابل تنظیمتر و بیانگرتر از همیشه ایجاد کنند.
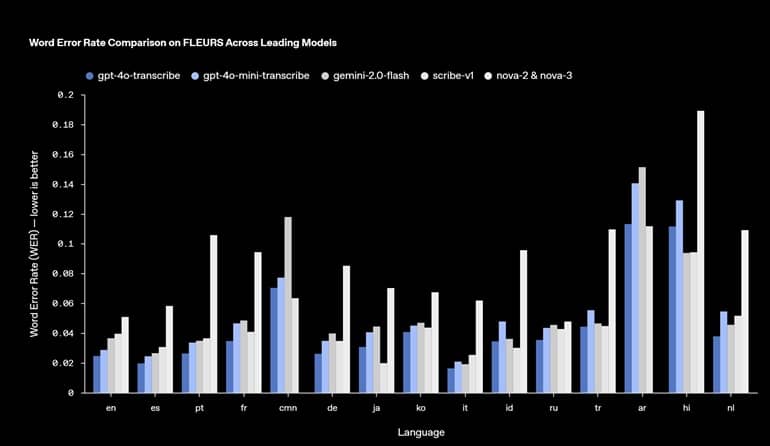
مدلهای جدید تبدیل گفتار به متن OpenAI، با نامهای gpt-4o-transcribe و gpt-4o-mini-transcribe، بهبودهای چشمگیری در نرخ خطای کلمات، تشخیص زبان و دقت نسبت به مدلهای قبلی Whisper ارائه میدهند. این پیشرفتها از طریق یادگیری تقویتی و آموزش گسترده با استفاده از مجموعه دادههای صوتی متنوع و با کیفیت بالا به دست آمدهاند.
OpenAI ادعا میکند که مدلهای صوتی جدید آنها توانایی بهتری در درک ظرافتهای گفتار، کاهش اشتباهات تشخیص و بهبود قابلیت اطمینان در تبدیل گفتار به متن دارند، حتی در شرایطی که ورودی صوتی شامل لهجهها، محیطهای پر سر و صدا و سرعتهای مختلف گفتار باشد.
مدل gpt-4o-mini-tts جدیدترین مدل تبدیل متن به گفتار است که قابلیت هدایتپذیری بهتری ارائه میدهد. توسعهدهندگان اکنون میتوانند به مدل دستور دهند که چگونه محتوای متنی را بیان کند. با این حال، در حال حاضر این مدل به صداهای مصنوعی و از پیش تنظیمشده محدود است. هزینههای مدلهای مختلف به شرح زیر است:
- gpt-4o-transcribe: حدود 0.6 سنت در هر دقیقه
- gpt-4o-mini-transcribe: حدود 0.3 سنت در هر دقیقه
- gpt-4o-mini-tts: حدود 1.5 سنت در هر دقیقه
تیم OpenAI در مورد مدلهای صوتی جدید خود اظهار داشت:
با نگاه به آینده، ما قصد داریم به سرمایهگذاری در بهبود هوش و دقت مدلهای صوتی خود ادامه دهیم و راههایی را برای توسعهدهندگان فراهم کنیم تا بتوانند صداهای سفارشی خود را ایجاد کنند و تجربههای شخصیسازیشدهتری را ارائه دهند که با استانداردهای ایمنی ما همخوانی داشته باشد.
این مدلهای صوتی جدید اکنون از طریق API برای تمامی توسعهدهندگان در دسترس هستند. همچنین، OpenAI از یکپارچگی با Agents SDK خبر داده که به توسعهدهندگان امکان میدهد بهراحتی ایجنت های صوتی ایجاد کنند. برای تجربههای گفتار به گفتار با تأخیر کم، OpenAI استفاده از Realtime API را توصیه میکند.