شرکت بایدو بهتازگی مدل جدیدی با نام PP-OCRv5 را در حوزهی تشخیص نویسه (OCR) معرفی کرده است. این مدل که اکنون از طریق پلتفرم Hugging Face در دسترس قرار دارد، با هدف ارائهی عملکرد دقیق در تشخیص متن، در عین حفظ ساختار فشرده و سبک طراحی شده است. در حالی که مدلهای بزرگمقیاس بینایی-زبانی در بسیاری از وظایف هوش مصنوعی عملکرد چشمگیری دارند، در تشخیص دقیق متنهای ساختاریافته با چالشهایی مواجهاند.
PP-OCRv5 برای رفع این محدودیتها توسعه یافته و از دو مرحله اصلی تشکیل میشود: ابتدا محل قرارگیری متن در تصویر را شناسایی میکند و سپس محتوای آن را استخراج مینماید. این رویکرد موجب افزایش دقت در تعیین موقعیت متن و ترسیم کادرهای دقیق پیرامون آن میشود (قابلیتی حیاتی برای استخراج داده از اسناد یا تحلیل فرمها). از نظر بهرهوری، این مدل تنها 0.07 میلیارد پارامتر دارد که در مقایسه با مدلهای عظیم موجود، بسیار سبک محسوب میشود.
آزمایشهای انجامشده نشان دادهاند که PP-OCRv5 قادر است با استفاده از پردازنده اینتل Xeon بیش از 370 نویسه در ثانیه را پردازش کند؛ بهطوریکه میتوان آن را روی رایانههای معمولی یا حتی دستگاههای لبهای (بدون نیاز به زیرساختهای سنگین سروری) اجرا کرد. در آزمونهای مقایسهای، این مدل عملکرد بهتری نسبت به مدلهای مطرحی چون GPT-4o، Gemini 2.5 Pro و Qwen2.5-VL در وظایف OCR از خود نشان داده است.
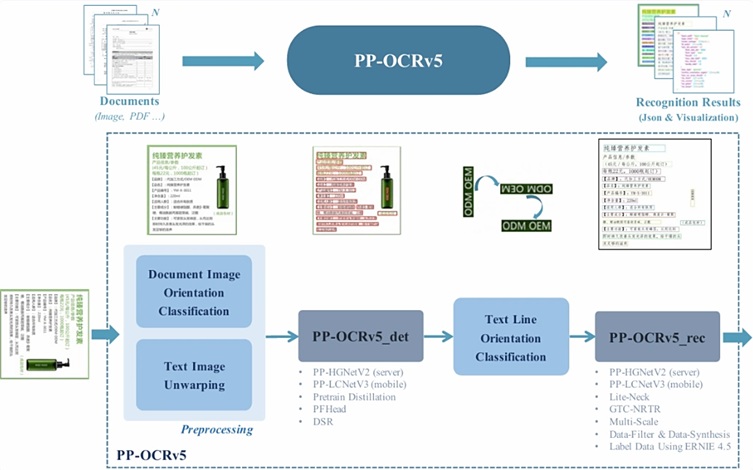
PP-OCRv5 توانایی تشخیص متنهای چاپی و دستنویس را داراست و از بیش از 40 زبان از جمله چینی ساده، چینی سنتی، ژاپنی، پینیین و انگلیسی پشتیبانی میکند. فرآیند فنی مدل شامل مراحل زیر است: اصلاح تصویر (رفع چرخش و اعوجاج)، شناسایی خطوط متنی، تعیین جهت قرارگیری متن و در نهایت تبدیل نویسهها به متن قابل خواندن. این فرآیند مختصات دقیق هر بخش متنی را ارائه میدهد که برای پردازش اسنادی مانند فاکتورها یا فرمهای ساختاریافته بسیار ضروری است.
بایدو این مدل را بهصورت عمومی از طریق Hugging Face منتشر کرده است. برای توسعهدهندگان و کسبوکارهایی که با حجم بالایی از اسناد چندزبانه سروکار دارند و به قابلیتهای دقیق OCR بدون بار پردازشی سنگین نیاز دارند، PP-OCRv5 گزینهای کاربردی و قابل اتکا بهشمار میرود