شیائومی بیشتر با گوشیهای هوشمند، تجهیزات خانه هوشمند و گاه بهگاه بهروزرسانیهای خودروهای برقی شناخته میشود. اکنون این شرکت خواهان جایگاهی در تحقیقات رباتیک نیز هست. این شرکت از Xiaomi-Robotics-0 رونمایی کرده که یک مدل متنباز از نوع بینایی-زبان-عمل (VLA) با 4.7 میلیارد پارامتر می باشد. این مدل برای ترکیب درک بصری، فهم زبانی و اجرای کنش در لحظه طراحی شده که به گفته شیائومی، هسته اصلی “هوش فیزیکی” را تشکیل میدهند.
به ادعای این شرکت، این مدل هماکنون رکوردهای پیشرو متعددی را در شبیهسازیها و آزمایشهای دنیای واقعی به ثبت رسانده است. در سطح کلان، مدلهای رباتیک از این دست یک حلقه بسته را حل میکنند: ادراک، تصمیمگیری و اجرا. یک ربات باید جهان را ببیند، درک کند چه وظیفهای از او خواسته شده، برنامهای را تعیین و سپس آن را بهراحتی اجرا کند. شیائومی میگوید Xiaomi-Robotics-0 بهطور خاص برای ایجاد تعادل میان درک گسترده و کنترل حرکتی دقیق ساخته شده است.
1. مدل Xiaomi-Robotics-0 بر دو مؤلفه اصلی استوار است
برای این منظور، این مدل از معماری به نام Mixture-of-Transformers (MoT) استفاده میکند و وظایف را میان دو مؤلفه اصلی تقسیم میکند. مؤلفه نخست، یک مدل زبانی-بصری (VLM) است که نقش “مغز” را ایفا میکند. این مدل برای تفسیر دستورالعملهای انسانی (حتی دستورات مبهمی مانند “لطفاً حوله را تا کن”) و درک روابط فضایی از ورودی بصری با وضوح بالا آموزش دیده است. این بخش مسئول تشخیص اشیاء، پاسخ به پرسشهای بصری و استدلال منطقی است.
مؤلفه دوم چیزی است که شیائومی آن را “کارشناس عمل” مینامد. این بخش حول یک ترانسفورمر پخش چندلایه (DiT) ساخته شده است. به جای تولید یک کنش منفرد در هر بار، چیزی به نام تکهعمل (Action Chunk) با استفاده از تکنیکهای تطبیق جریان برای حفظ دقت و نرمی حرکت تولید میکند (که آن را میتوان دنبالهای از حرکات در نظر گرفت).
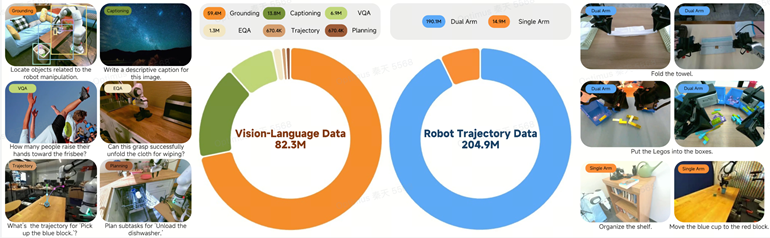
یکی از مشکلات رایج در مدلهای VLA این است که وقتی یاد میگیرند کنشهای فیزیکی انجام دهند، معمولاً بخشی از تواناییهای درکی اولیه خود را از دست میدهند. شیائومی ادعا میکند با آموزش همزمان مدل بر روی دادههای چندوجهی و دادههای کنشی از این مشکل جلوگیری کرده است. نتیجه، دستکم در تئوری، سیستمی است که همچنان میتواند درباره جهان استدلال کند و همزمان بیاموزد چگونه در آن حرکت کند.
2. فرایند آموزش چگونه است؟
فرایند آموزش در مراحل انجام میشود. نخست، سازوکاری به نام Action Proposal، مدل زبانی-بصری را وادار میکند تا ضمن تفسیر تصاویر، توزیعهای احتمالی کنش را پیشبینی کند. این کار بازنمایی درونی مدل از آنچه میبیند را با نحوه اجرای کنشها همسو میسازد. پس از آن، مدل زبانی-بصری ثابت (Frozen) میشود و ترانسفورمر پخش بهطور جداگانه آموزش میبیند تا دنبالههای کنشی دقیق را از نویز تولید کند.
شیائومی همچنین به مشکل عملی دیگری به نام تأخیر استنتاج (Inference Latency) پرداخته است؛ یعنی زمانی که فاصله میان پیشبینیهای مدل و حرکت فیزیکی میتواند باعث مکثهای ناخوشایند یا رفتار ناپایدار شود. شیائومی میگوید از استنتاج ناهمگام (Asynchronous Inference) بهره گرفته و محاسبات مدل را از عملکرد ربات جدا کرده است؛ به این ترتیب حرکات حتی اگر مدل برای فکر کردن زمان بیشتری نیاز داشته باشد، پیوسته باقی میماند.
برای بهبود پایداری، شیائومی از تکنیک Clean Action Prefix استفاده میکند که کنش پیشبینیشده پیشین را دوباره به مدل بازخورد میدهد تا حرکتی نرم و بدون لرزش در طول زمان تضمین شود. همزمان، یک نقاب توجه 8-شکل مدل را به سمت ورودی بصری جاری سوق میدهد تا از اتکای بیش از حد به حالات گذشته جلوگیری کند. هدف این است که ربات در برابر تغییرات ناگهانی محیط واکنشپذیرتر باشد.
3. بنچمارک Xiaomi-Robotics-0
بر اساس گزارشها، Xiaomi-Robotics-0 در آزمونهای بنچمارک در شبیهسازهای LIBERO، CALVIN و SimplerEnv به نتایج پیشرو دست یافته و عملکرد حدود 30 مدل دیگر را پشت سر گذاشته است. جالبتر اینکه، شیائومی این مدل را بر روی یک پلتفرم ربات دو-بازو در آزمایشهای دنیای واقعی پیادهسازی کرده است. به گفته شیائومی، در کارهای بلندمدت مانند تا کردن حوله و باز کردن قطعات لگو، ربات هماهنگی چشم و دست پایدار از خود نشان داده و اشیاء سخت و نرم را بدون اختلال آشکار مدیریت کرده است.
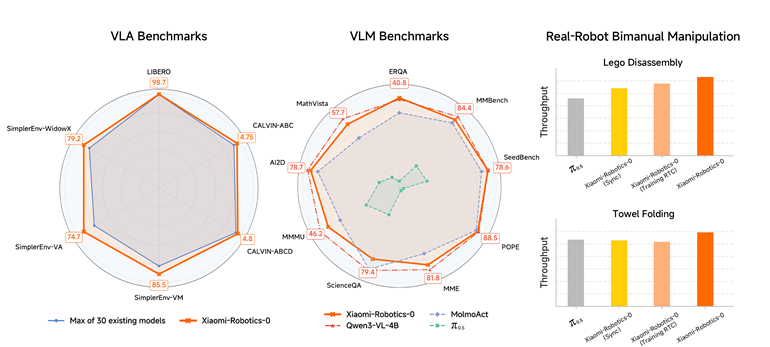
برخلاف سیستمهای VLA پیشین که اغلب با شروع آموزش کنش، توانایی استدلال چندوجهی خود را قربانی میکردند، مدل Xiaomi-Robotics-0 تواناییهای بصری و زبانی قوی خود را حفظ کرده است؛ بهویژه در کارهایی که ادراک را با کنش فیزیکی درمیآمیزند.